人工智慧(Artificial Intelligence,簡稱 AI)在 21 世紀的今日已大量運用在生活中,近年掀起熱議的 ChatGPT、AI 生成圖像與影片、電動車自駕系統等,都是 AI 技術的延伸應用。多數 AI 的研發秉持改善人類生活的人文思維,除了仰賴工程師的先進技術,更需要人文社會領域人才的加入。中央研究院「研之有物」專訪院內人文社會科學研究中心蔡宗翰研究員,帶大家釐清什麼是 AI?文科人與工程師合作時,需具備什麼基本 AI 知識?AI 如何應用在人文社會領域的工作當中?
認識 AI 的第一步,我們先從分辨什麼是 AI 做起。現在的數位工具五花八門,究竟什麼才是 AI 的應用?真正的 AI 有什麼樣的特徵?
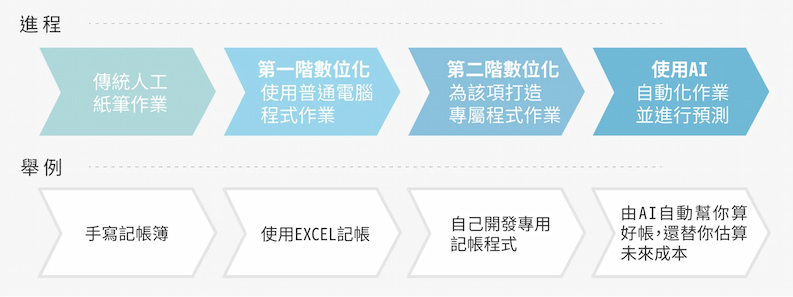
基本上,有「預測」功能的才是 AI,你無法得知每次 AI 會做出什麼判斷。如果只是整合資料後視覺化呈現,這人類手工操作就辦得到,那就不是 AI。
數位化到 AI 自動化作業的進程與舉例(Source:研之有物〔資料來源|蔡宗翰〕)
蔡宗翰以今日常見的語音辨識系統為例。大家可以試著對 Siri、Line 或 Google 上的語音辨識系統講一句話,你會發現自己無法事先得知將產生什麼文字或回應,結果可能正是你想要的、也可能牛頭不對馬嘴。此現象點出 AI 與一般數位工具最明顯的不同:AI 無法百分之百正確!
因此,AI 的運作需建立在不斷訓練、測試與調整的基礎上,盡量維持 80、90% 的準確率。在整個製程中最重要的就是訓練階段,工程師化身老師,必須設計一套學習方法,提供有助學習的豐富教材。而 AI 則是史上最認真的學生,可以穩定、一字不漏、日以繼夜地學習所有課程。
AI 的學習方法主要分為「非監督式學習」、「監督式學習」。非監督式學習是將大批資料提供給 AI,讓它根據工程師所定義的資料相似度算法,學會將相似資料分在同一堆,再由人類檢視並標注每堆資料對應的類別,進而產生監督式學習所需的訓練資料。而監督式學習則是將大批「資料」和「答案」提供給 AI,讓它逐漸學會將任意資料對應到正確答案。
Source:研之有物(資料來源|蔡宗翰、圖片來源|Unsplash)
學習到一定階段後,工程師會出試題,測試 AI 的學習狀況,如果成績只有 60、70 分,AI 會針對答錯的地方調整自己的觀念,而工程師也應該與專門領域專家一起討論,想想是否需補充什麼教材,讓 AI 的準確率再往上提升。
就算 AI 最後通過測試、可以正式上場工作,也可能因為時事與技術的推陳出新,導致準確率下降。這時,AI 就要定時進修,針對使用者回報的錯誤進行修正,不斷補充新的學習內容,讓自己可以跟得上最新趨勢。
在了解 AI 的基本特徵與訓練流程後,蔡宗翰建議:文科人可以看一些視覺化的操作影片,加深對訓練過程的認識,並實際參與檢視與標注資料的過程。現在網路上也有很多 playground,可以讓初學者練習怎麼訓練 AI,有了上述基本概念與實務經驗,就可以降低跟工程師的溝通障礙。
AI 皇冠上的明珠:能騙過人類的「自然語言處理」
AI 的應用領域相當廣泛,而蔡宗翰專精的是「自然語言處理」。問起當初想投入該領域的原因,他充滿自信地回答:因為自然語言處理是「AI 皇冠上的明珠」!
這顆明珠開創 AI 發展的諸多可能性,可以快速讀過並分類所有資料,整理出能快速檢索的結構化內容,也可以如同真人般與人類溝通。
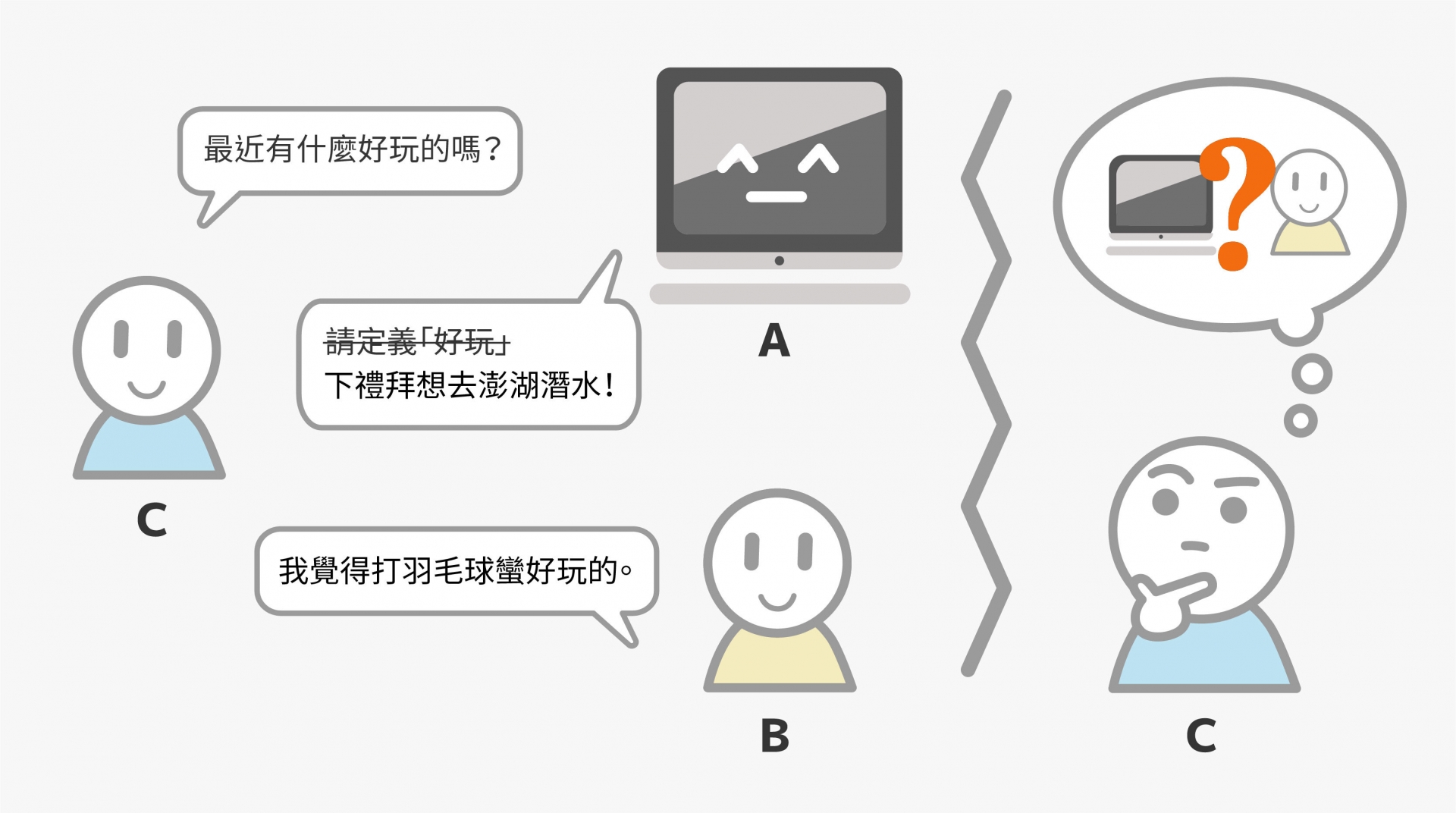
著名的「圖靈測試」(Turing test)便證明了自然語言處理如何在 AI 智力提升上扮演關鍵角色。
1950 年代,傳奇電腦科學家艾倫・圖靈(Alan Turing)設計了一個實驗,用來測試 AI 能否表現出與人類相當的智力水準。首先實驗者將 AI 架設好,並派一個人操作終端機,再找一個第三者來進行對話,判斷從終端機傳入的訊息是來自 AI 或真人,如果第三者無法判斷,代表 AI 通過測試。
圖靈測試:AI(A)與真人(B)同時傳訊息給第三者(C),如果 C 分不出訊息來自 A 或 B,代表 AI 通過實驗。(Source:研之有物)
換言之,AI 必須擁有一定的智力,才可能成功騙過人類,讓人類不覺得自己在跟機器對話,而這有賴自然語言處理技術的精進。目前蔡宗翰的研究團隊有將自然語言處理應用在:人文研究文本分析、新聞真偽查核,更嘗試以合成語料訓練臺灣人專用的 AI 語言模型。
目前幾乎所有正史、許多地方志都已數位化,而大量數位化的經典更被主動分享到「Chinese Text Project」平台,讓 AI 自然語言處理有豐富的文本資料可以分析,包含一字不漏地快速閱讀大量文本,進一步畫出重點、分門別類、比較相似之處等功能,既節省整理文本的時間,更能橫跨大範圍的文本、時間、空間,擴展研究的多元可能性。















{kind=link}