
資料並不客觀,這是事實,因此在分析資料集時,務必考量到當中所含的偏見。白宮在 2016 年提出警告:「把資料轉換成資訊的演算系統,並非絕對可靠,畢竟這些系統的運作仰賴的是並不完美的輸入、邏輯、機率和演算法設計者。」
舉例來說,從犯罪數據看不出所有的犯罪活動,這些數據反映的只是報案資料而已,況且報案資料又會因為很多因素而有偏差現象。某社區可能特別喜歡叫警察,另一個社區卻未必如此。非法移民較多的移民密集社區,打電話請警察到附近處理小犯罪事件的頻率,是否跟那些不在乎同鄉被驅逐出境的社區一樣?累積了十幾張違停罰單未繳的人,有沒有可能報案說自己的車子被偷了?
這樣看來,報案資料反映的其實是信任度與社區生態那些在表面上很容易被忽略的差異。舉例來說,美國司法統計局(Bureau of Justice Statistics)就發現,像是仇恨犯罪和性侵之類的特定犯罪,有長期被低報的情況,意思是說,這些犯罪很有可能落在報案資料的熱點地圖之外。
人權資料分析團體(Human Rights Data Analysis Group,簡稱 HRDAG)是位於舊金山教會區的非營利組織,致力於運用嚴謹的資料分析,解決全球侵犯人權的議題,它就曾經針對犯罪資料的偏差,以及演算法如何強化警察局的反應偏差做過研究。
皇家統計學會(Royal Statistical Society)的期刊《顯著性》(Significance)也發表過一項研究,調查由 PredPol 這家專門以資料科學來預測及預防犯罪的公司所推出的一款預測性警務演算法,其功效何在。該演算法可以通報警察局哪裡是部署警力的最佳地點,以期預防可能的犯罪情事。
克里斯蒂安・蘭姆(Kristian Lum)和威廉・以塞克(William Isaac)這兩位作家決定運用一款屬於少數能公開發表於專業期刊中的演算法,來分析可公開取得的加州奧克蘭毒品犯罪紀錄資料。
蘭姆和以塞克從一些其他資源,比方說美國藥物使用與健康全國調查(National Survey on Drug Use and Health),蒐集到奧克蘭毒品犯罪分布資料,來補充原有的資料集。從他們的資料可以看出,大致上各個族裔都有使用毒品的現象,但相應的毒品逮捕紀錄卻非如此。
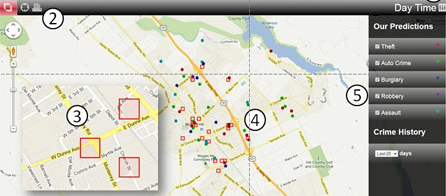
根據美國公民自由聯盟(American Civil Liberties Union,簡稱 ACLU)2013 年的報告指出,非裔美國人因持有大麻而被逮捕的機率是白人的 3.73 倍,即使這兩個族裔使用大麻的機率差不多一樣。ACLU 把逮捕率與實際毒品使用率之間的落差,歸咎於種族面貌辦案方式、攔截盤查程序及逮捕配額。HRDAG 也發現,毒品犯罪在奧克蘭各地的分布狀況很平均,但毒品的查扣行動卻集中在一些特定地點,主要是西奧克蘭和福特維爾這兩個絕大多數都是非白人族裔居住的低收入社區。
也因此,犯罪活動的發生地點這方面的資訊,極有可能在統計數據上出現偏見,所以如果真如演算法建議的,派遣大批警力到犯罪率較高的那一帶社區,反而加重偏見,因為在這些地區加派更多警力,就意味著很有可能會出現更多逮捕行動。較高的逮捕數據又會被放入演算法中,演算法又利用該資訊來確認它所推算的特定社區有較高犯罪率的預測是正確的,進一步加深了最初的偏見,最後變成扭曲的惡性循環現象。
在史上第一份針對大數據與公民權利的報告中,白宮特別強調這兩種影響力重大的新機會之外,同時也提出警告:「若無審慎的分析,這些創舉很容易製造歧視、強化偏見,而蒙蔽了機會。」舊金山法院試用演算法來提供判決建議,倫敦又有利用演算法管理派遣人力的做法,這些都超出了傳統執法的範疇。科技作家奧姆・馬利克(Om Malik)稱之為「資料達爾文主義」(data Darwinism),在這種現象之下,一個人的數位聲譽會變成他的使用門檻。
凱西・歐尼爾(Cathy O’Neil)是哥倫比亞大學新聞學院前資料實作主任,著有暢銷書《大數據的傲慢與偏見:一個「圈內數學家」對演算法霸權的警告與揭發》(Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy),她對大數據更是小心為上。她表示:「宣揚大數據的傳道者不少,但我不在其列。」她認為演算法就像她所說的「被拿來當做武器使用」,好讓歧視永遠存在。

演算法會利用數學來掩飾偏見,而歐尼爾特別指出這種有害的演算法通常具有五大特質:(1)以特定族群為目標;(2)演算方式不透明,目標族群不了解其如何推算;(3)對許多人造成衝擊,或者也可以說有「規模」;(4)建構者以目標族群不苟同的方式界定演算法的成功(一般所謂的成功通常是指幫組織省錢);(5)造成惡性循環。
另一個特別有啟發性的例子,可以印證歐尼爾的論點。紐約大學史登商學院商業智慧及資料探勘學兼任教授克勞蒂亞・柏利希(Claudia Perlich)是一位資料科學家,她在一場名為「有了資料還不夠」(All the Data and Still Not Enough)的演講中,探討一個她因為好幾個研究活動而勝出的資料探勘競賽,叫做「探索與資料探勘獎」(Knowledge Discovery and Data Mining Cup)。
2008 年,西門子醫療(Siemens Medical)邀請幾個研究團隊參加比賽,用功能性磁振造影所拍攝的胸部影像含有乳癌患者的可能性,來排序候選區域。每一個團隊都拿到來自 10 萬個候選區域的 117 項特徵。在 1712 位病患的胸部影像當中,有 118 位至少有一個惡性候選區域。西門子也請這些團隊研究每個影像的 117 項特徵,其中有些特徵或許可作為預測之用,指出該病患是否罹患癌症。各團隊被要求建構模型,分析這 117 項特徵,以研究這種預測模型對診斷候選區域乃至於最終診斷病患的可靠性為何。
柏利希的團隊隸屬於國際商業機器(IBM)的華生研究(Watson Research)。他們在探索資料集時,注意到病患編號小的病患,其癌症發生率似乎很高,遠超過預期的 10% 左右。把病患識別碼加入預測模型後(沒有哪位稱職的資料科學家想到這一點),他們觀察到預測績效顯著上升。
病患識別碼理論上是隨機產生的十位數數字,只作為識別病患之用,這串數字本來就不該跟功能性磁振造影資料所提供的乳癌發生率有關,該團隊的觀察發現卻非如此。病患識別碼被劃分到數組內,在某組中,36% 的病患有惡性部位,然而在其他兩組中,只有 1% 的病患有癌症。病患識別碼不該屬於能指出乳癌關聯性的資料特徵,因此這個現象讓柏利希的團隊大感不解。根據進一步調查,最能解釋這種現象的假說,就是資料必定是從四個來源取得。
從不同來源蒐集資料一向是資料分析的良好習慣做法,但在這個案例中,彙整資料集的人並未明確指出某些病患的資料是取自於癌症篩選場所,某些則來自癌症治療場所。由於治療場所的癌症發生率明顯較高,因此病患識別碼當中代表不同區域的數字,就成了可預測的指標。
雖然柏利希的團隊建構了預測更準的模型,可分析磁振造影影像中數千筆的特徵,但進一步檢驗後他們才發現,此模型唯一可靠的預測,就是指出病患正在接受癌症治療,還是處於診斷過程當中。此模型乍看之下很有效率,但效果「好」到令人難以置信。由此可見,資料的漏洞會吞噬模型的預測能力。
「我們該如何著手控管這些深入人類生活的數學模型?」凱西.歐尼爾提出這個問題。
「數據不會消失,電腦也不會,更別提數學了。我們會愈來愈依賴預測模型之類的工具來經營我們的機構、部署我們的資源以及管理我們的生活⋯⋯這些模型的構成不只是靠資料而已,我們在判斷該留意及該省略哪些資料時所做的決定也會影響模型的構成。這些決定牽涉到的不只是後勤、利益和效率方面的問題,最重要的是根本上的道德問題。」
蒐集和解讀資料時出現的人為誤差,必須透過人類的分析來修正,這樣的工作自當由受過良好人文與社會科學教育的人來做。這些領域出身的人會針對資料蒐集來源的社會背景脈絡提供寶貴觀點,他們也具備必要的能力,可以詮釋和傳達他們從資料中找到的新發現。
我們無法排除社會中的偏見,但我們可以結合文科人與理科人的專長,把演算法訓練成能夠更有效地過濾掉人類皆有的弱點,並減輕其造成的偏誤。











{kind=link}
{kind=link}
{kind=link}